Test Docling
测试开源项目docling的功能
docling
- 仓库地址:https://github.com/DS4SD/docling
- Usage文档: https://ds4sd.github.io/docling/usage/#control-pdf-table-extraction-options
- 特点:能读取流行的文档格式(PDF、DOCX、PPTX、XLSX、图片、HTML、AsciiDoc 和 Markdown),并导出为 HTML、Markdown 和 JSON。
默认的Fast模式
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from docling.document_converter import DocumentConverter
import os
import os.path
# 创建output目录(如果不存在)
output_dir = "output"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
source = "contract.docx" # document per local path or URL
# 获取源文件名(不含扩展名)
source_name = os.path.splitext(os.path.basename(source))[0]
converter = DocumentConverter()
result = converter.convert(source)
# 构建输出文件路径
output_path = os.path.join(output_dir, f"{source_name}.md")
# 将转换结果写入文件
with open(output_path, "w", encoding="utf-8") as f:
f.write(result.document.export_to_markdown())
print(f"转换完成,文件已保存至: {output_path}")测试效果如下:
文本

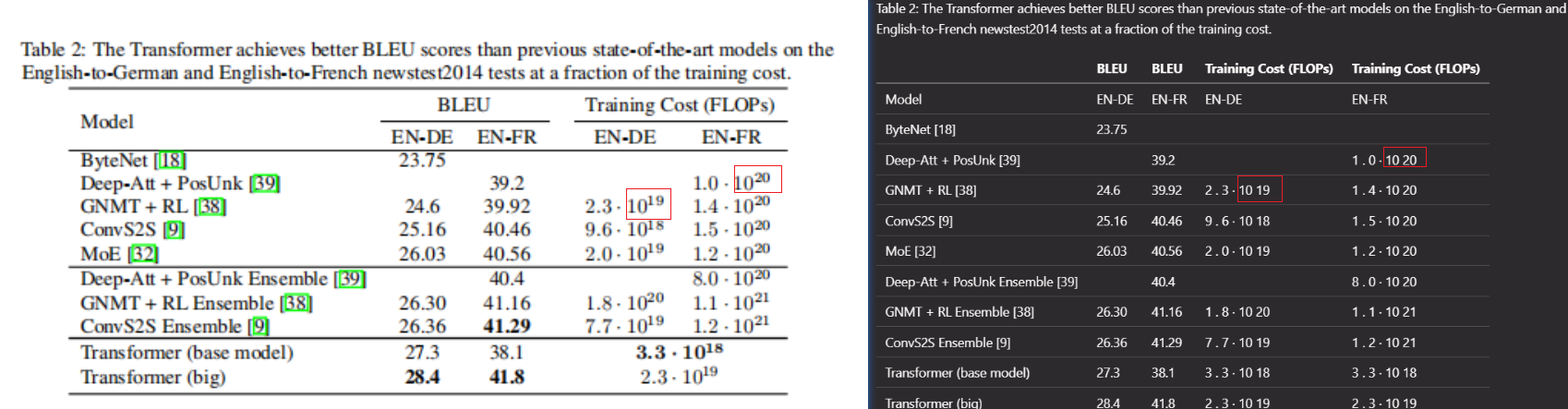
- 复杂图片,没有识别也没有保留;数字、括号识别很精准

- 对表格的识别很好,但对公式、指数等识别不准确;不过作者在readme的Coming soon中提交到了,未来会补充;

Accurate模式
Usage文档中描述:Since docling 1.16.0: You can control which TableFormer mode you want to use. Choose between TableFormerMode.FAST (default) and TableFormerMode.ACCURATE (better, but slower) to receive better quality with difficult table structures;即选择TableFormerMode.ACCURATE (better, but slower) 可以识别更复杂的表格结构获得更好的质量,但速度会变慢。
需要在默认的OCR引擎上添加中文支持
pipeline_options.ocr_options.lang = ["ch_sim", "en"] # example of languages for EasyOCR示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37from docling.datamodel.base_models import InputFormat
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.pipeline_options import PdfPipelineOptions, TableFormerMode
import os
import os.path
pipeline_options = PdfPipelineOptions(do_table_structure=True)# 开启表格结构识别
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE # use more accurate TableFormer model
pipeline_options.ocr_options.lang = ["ch_sim", "en"] # example of languages for EasyOCR
doc_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
}
)
# 创建output目录(如果不存在)
output_dir = "outputAccurate"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
source = "test5.pdf" # document per local path or URL
# 获取源文件名(不含扩展名)
source_name = os.path.splitext(os.path.basename(source))[0]
# 构建输出文件路径
output_path = os.path.join(output_dir, f"{source_name}.md")
result = doc_converter.convert(source)
# 将转换结果写入文件
with open(output_path, "w", encoding="utf-8") as f:
f.write(result.document.export_to_markdown())
print(f"转换完成,文件已保存至: {output_path}")如下为测试结果,以发票为例,左边为Fast模式,右边为Accurate模式;
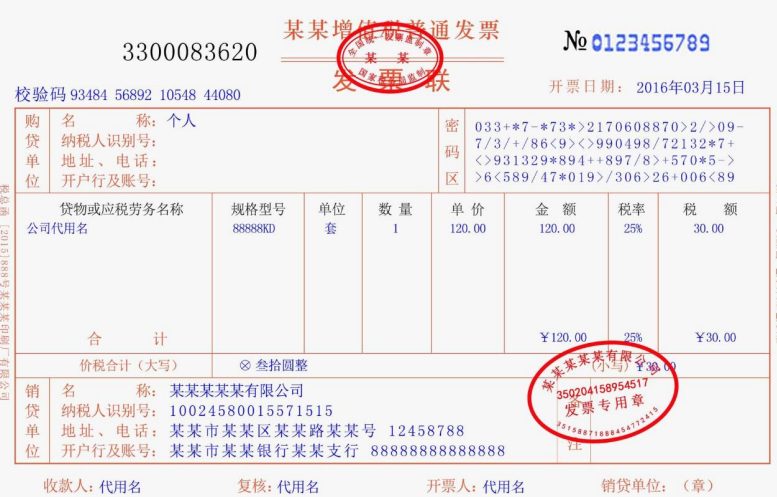
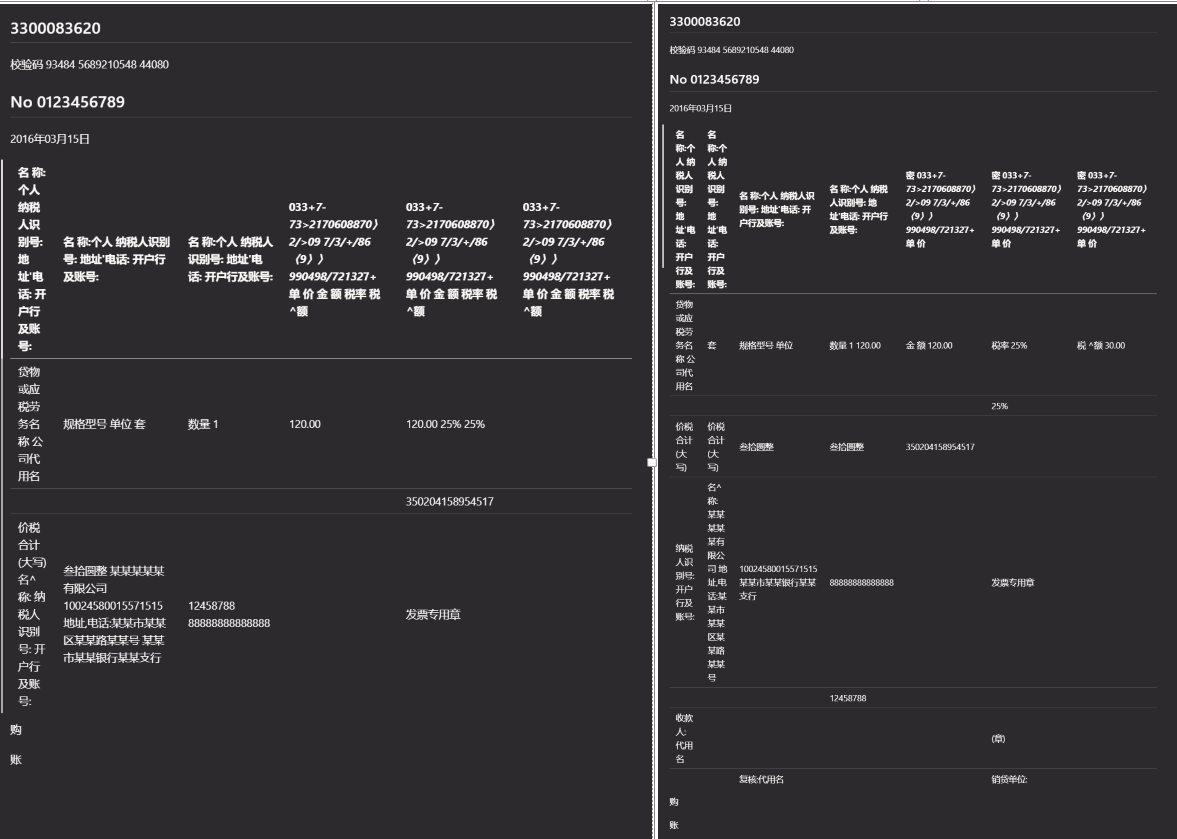
可以看出来,Accurate模式识别的布局确实更细致一些,但也有更多重复的地方;
最后还有一个AI集成功能没有测完
Test Docling
https://tolsz.me/2025/01/16/Test-Docling/