testMinerU
测试minerU的过程与结果
minerU
可本地部署的一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。转换成这两种格式的目的就是方便将数据提取出来更好地存储/传递给相关大模型进行逻辑处理提高解答的准确率;(大模型都是通过markdown或json格式的数据进行训练和响应的)
首先要配置相关环境
- 具体见 https://github.com/opendatalab/MinerU/blob/master/docs/README_Windows_CUDA_Acceleration_zh_CN.md?tab=readme-ov-file#command-line
- 每次使用之前,先conda activate MinerU 进入环墶
- GPU配置CUDA加速之后,速度明显提升好几倍,但是效果似乎没变;
运行命令
- 简单来讲主要功能:magic-pdf -p {pdf文件(夹)路径} -o {输出路径} -m {模式:ocr/text/auto(default)} –lang (语言:ch、en)
- 提示:选择正确的语言可以显著提高识别准确率。对于混合语言文档,建议使用自动检测模式(默认)。
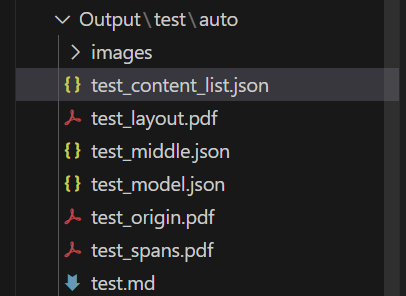
- 比如 magic-pdf -p test.pdf -o ./Output -m ocr –lang ch 后会在当前目录下生成一个Output文件夹,结构如下
- Output/相应pdf文件名/模式/识别结果
- 具体意义详见:https://mineru.readthedocs.io/en/latest/user_guide/tutorial/output_file_description.html
- 详见: https://mineru.readthedocs.io/en/latest/user_guide/quick_start/command_line.html
- 简单来讲主要功能:magic-pdf -p {pdf文件(夹)路径} -o {输出路径} -m {模式:ocr/text/auto(default)} –lang (语言:ch、en)
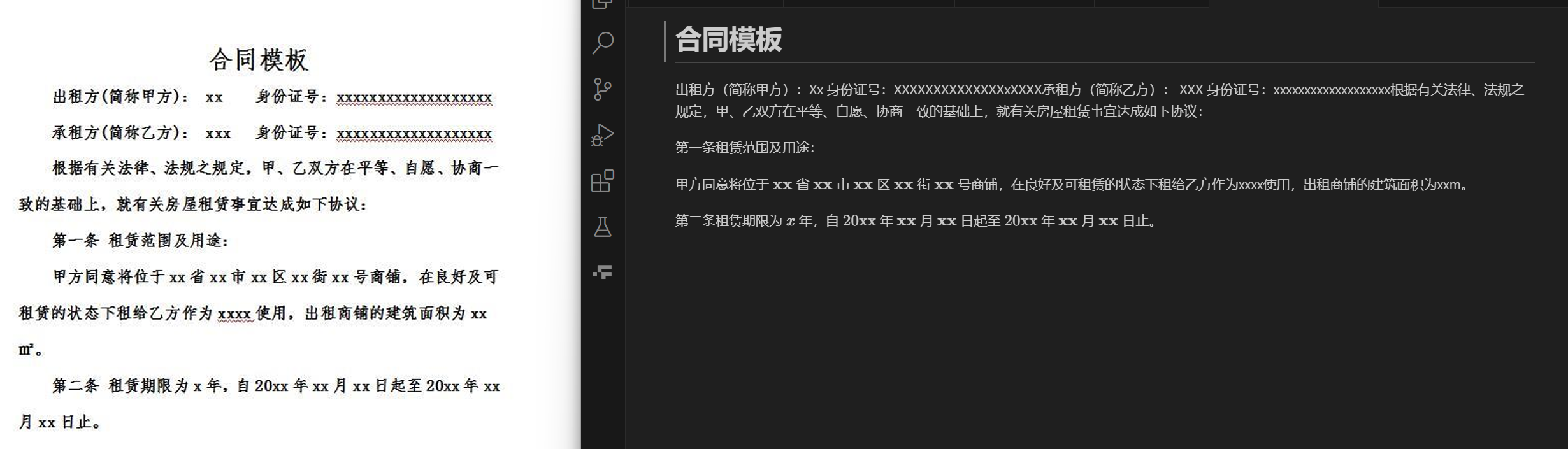
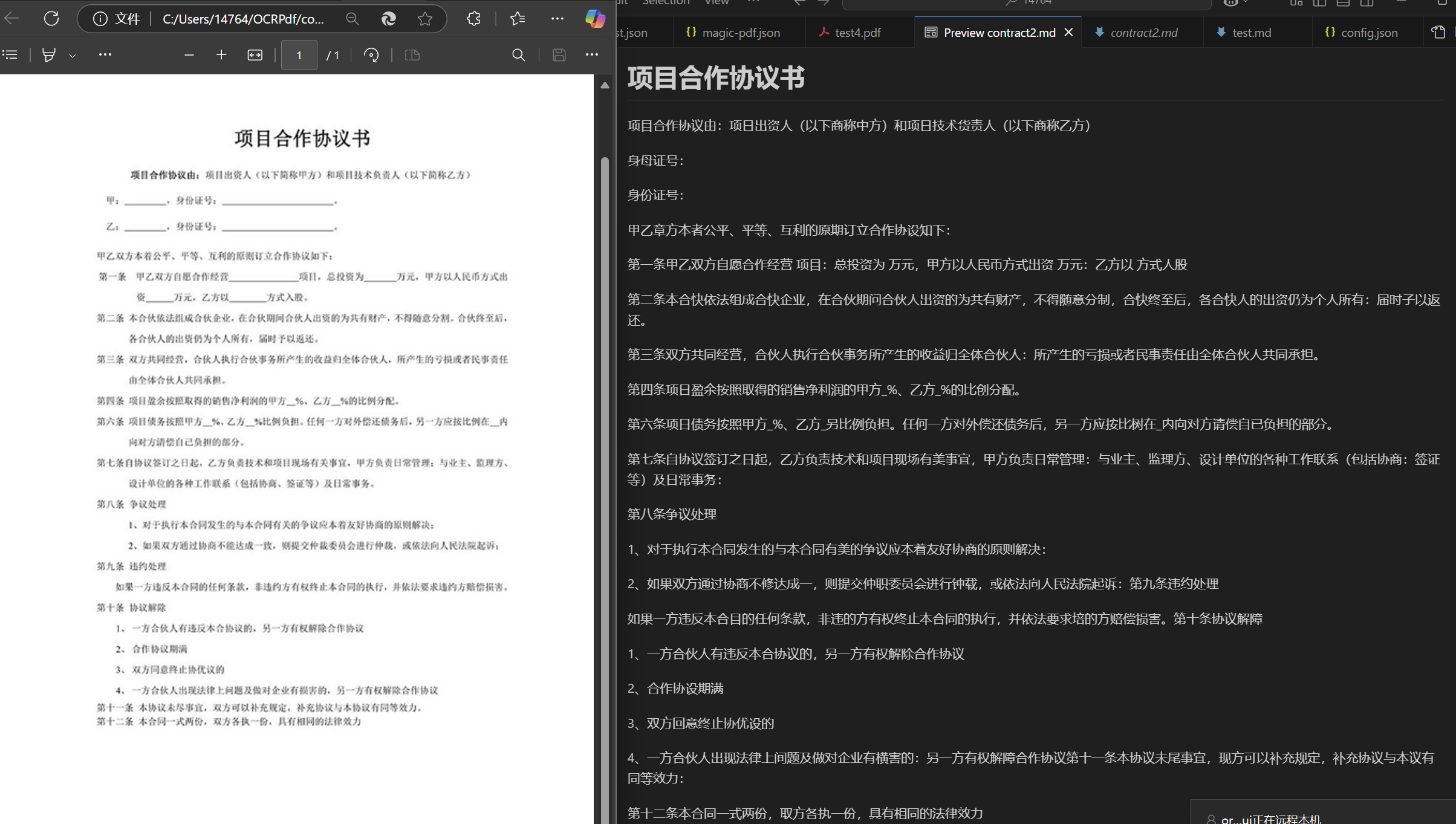
测试结果:类似于如下,排版比较简单的合同、文章等等大多是文字的图片,可以ocr识别出来提取文字;而像发票、车票等排版复杂的图片目前minerU识别不了,还是以图片的形式存在于markdown中,
合同、文章:
发票、车票
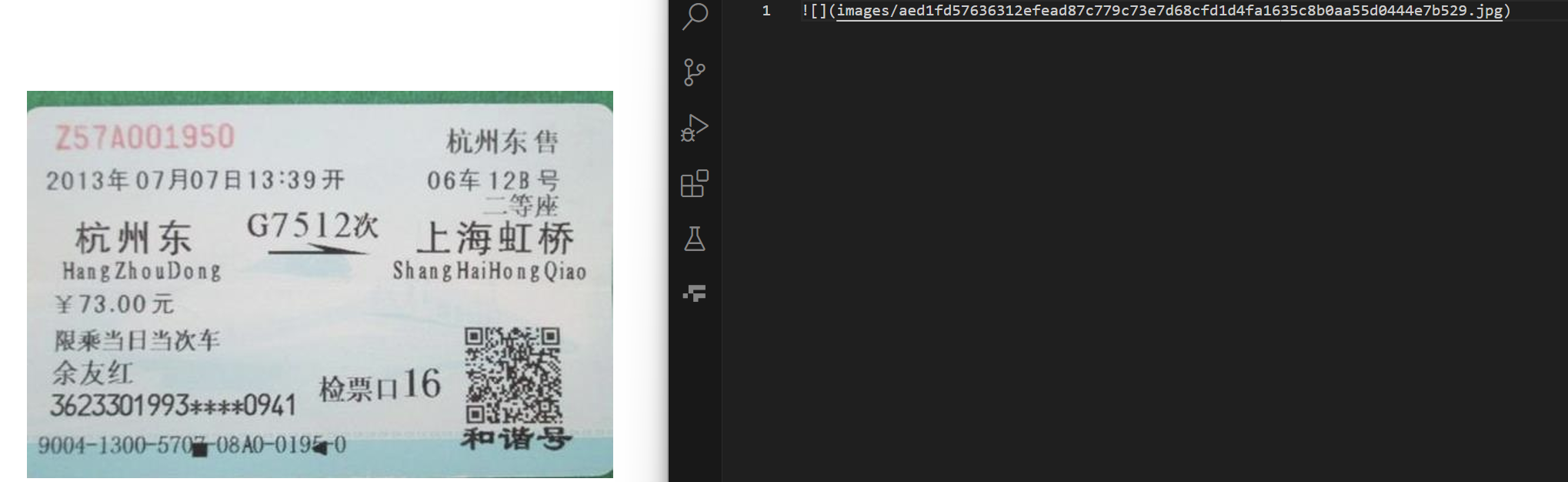
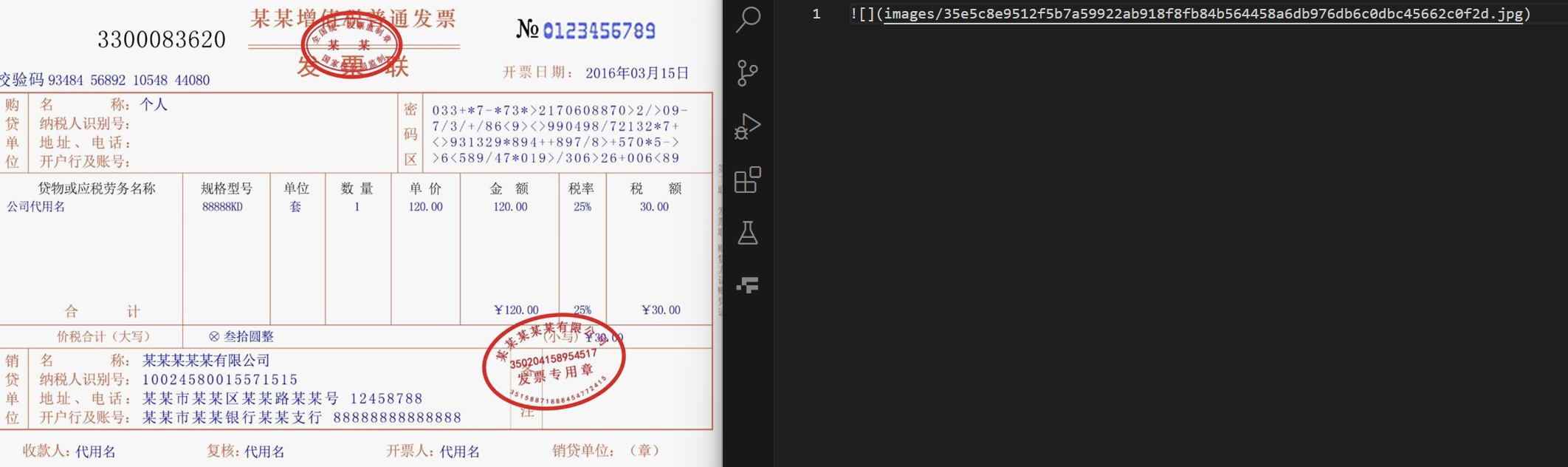
分析原因:
也许是没开GPU加速的原因?试试
- 开了之后,速度确实加快了很多,之前30-40s一张pdf,现在不到15s,时长取决于内容的多少,但是发票等图片还是以图片的形式存在于markdown中
谷歌之后发现github也有人提出类似的issue
查看项目readme.md文档
- 作者已在Known Issues 说明 some uncommon list formats may not be recognized.
尝试解决办法
- 不用命令行,改用python代码进行调用强制开启OCR
- 结果:无用
- 通过paddle去识别那些minerU识别不了的内容
- 我已提交issue,等待作者和大佬们升级项目
- 不用命令行,改用python代码进行调用强制开启OCR
testMinerU
https://tolsz.me/2025/01/06/testMinerU/